Hardware as Policy: Mechanical and ComputationalCo-Optimization using Deep Reinforcement Learning
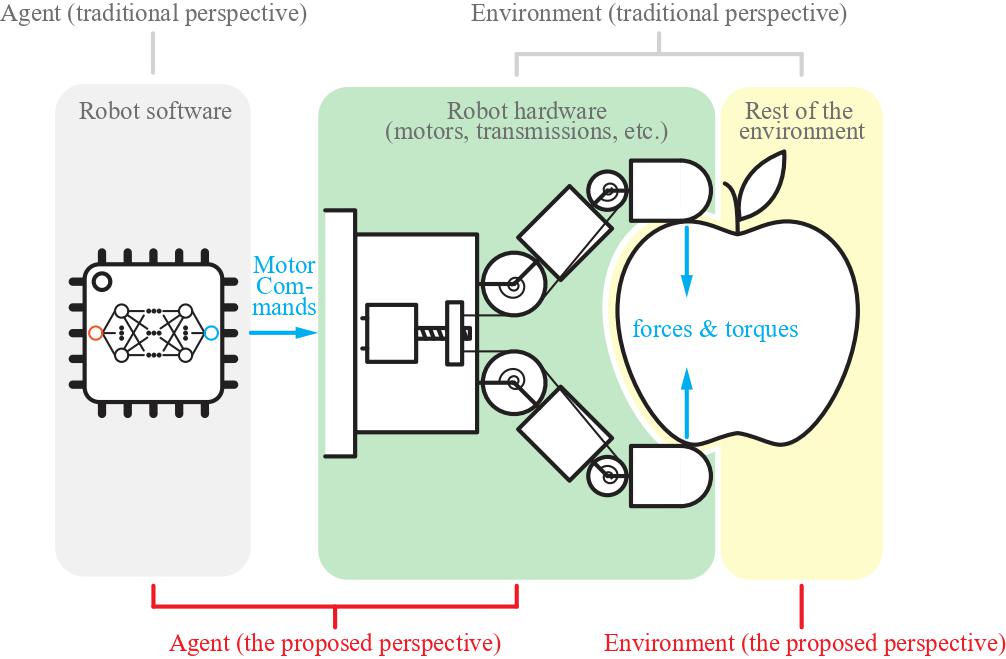
Deep Reinforcement Learning (RL) has shown great success in learning complex control policies for a variety of applications in robotics. However, in most such cases, the hardware of the robot has been considered immutable, modeled as part of the environment. In this study, we explore the problem of learning hardware and control parameters together in a unified RL framework. To achieve this, we propose to model the robot body as a ''hardware policy'', analogous to and optimized jointly with its computational counterpart. We show that, by modeling such hardware policies as auto-differentiable computational graphs, the ensuing optimization problem can be solved efficiently by gradient-based algorithms from the Policy Optimization family. We present two such design examples: a toy mass-spring problem, and a real-world problem of designing an underactuated hand. We compare our method against traditional co-optimization approaches, and also demonstrate its effectiveness by building a physical prototype based on the learned hardware parameters.
Paper
Latest version: here

Team



BibTeX
@inproceedings{chen2020hwasp,
title={Hardware as Policy: Mechanical and ComputationalCo-Optimization using Deep Reinforcement Learning},
author={Chen, Tianjian and He, Zhanpeng and Ciocarlie, Matei},
booktitle={Conference on Robotic Learning (CoRL)},
year={2020}
}Technical Summary Video (with audio)
Method Overview
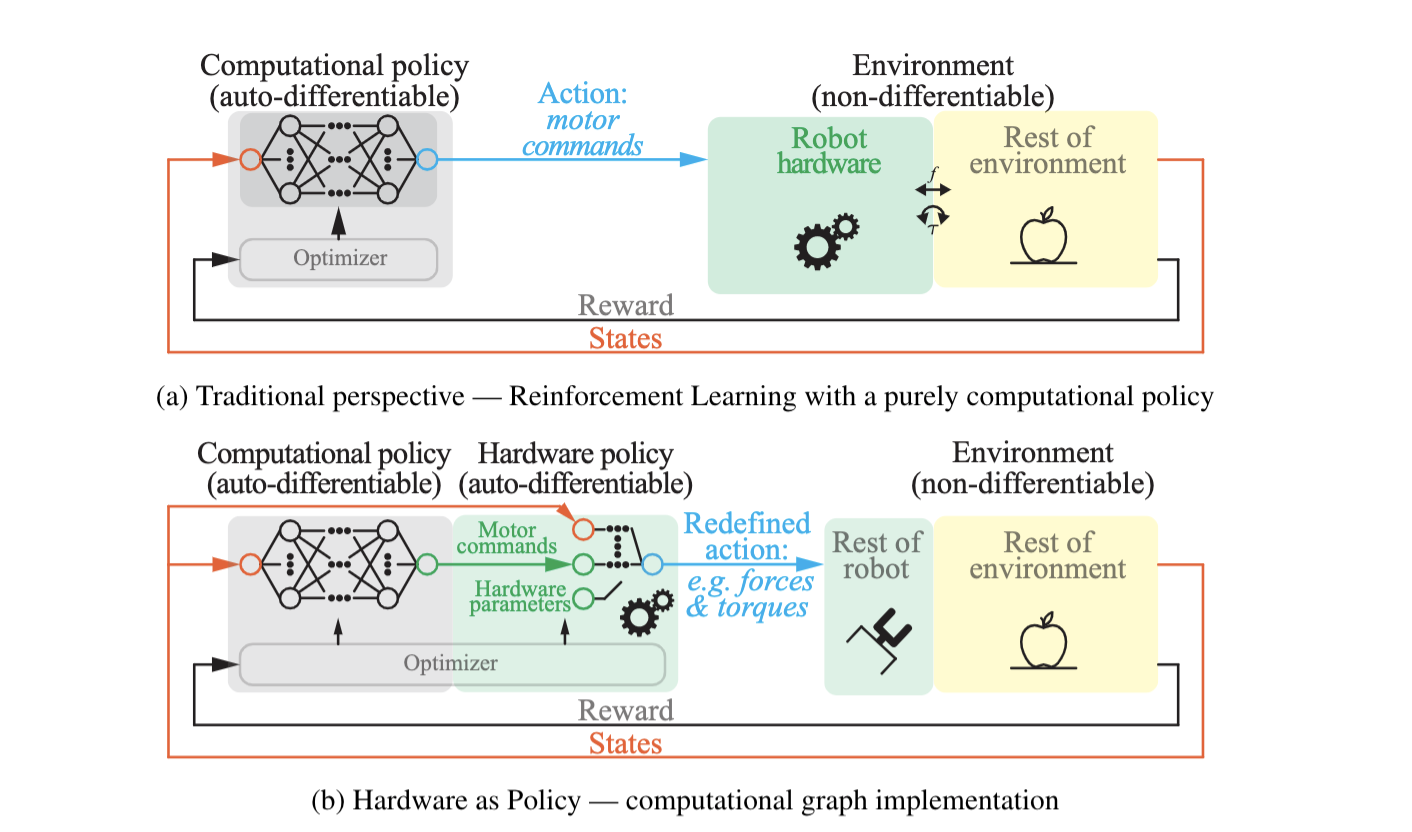
In this work, we purpose to consider hardware as policy, optimized jointly with the traditional computational policy using Reinforcement Learning (RL). By moving some part of the robot hardware from the non-differentiable environment and into the auto-differentiable agent/policy, the hardware parameters become parameters in the policy graph, analogous to and optimized in the same fashion as the neural network weights and biases. Therefore, the optimization of hardware parameters can be directly incorporated into the existing RL framework, and can use existing learning algorithms with minor changes only in the computational graphs.
Co-Design of an Underactuated Hand
HWasP can be applied to a real-world design problem: optimizing both the mechanism and the control policy for an underactuated robot hand. The hand we are optimizing is governed by an underactuated transmission mechanism: one motor actuates all joints by tendons in the flexion direction. Finger extension is passive, provided by preloaded torsional springs. The mechanical parameters that govern the behavior of this mechanism consist of tendon pulley radii in each joint, as well as stiffness values and preload angles for restoring springs. We tested our method with two grasping tasks: 1. top-down grasping with only z-axis motion for the palm movement (Z-Grasp); 2. top-down grasping with 3-dimensional palm motion (3D-Grasp).

Learning Performance
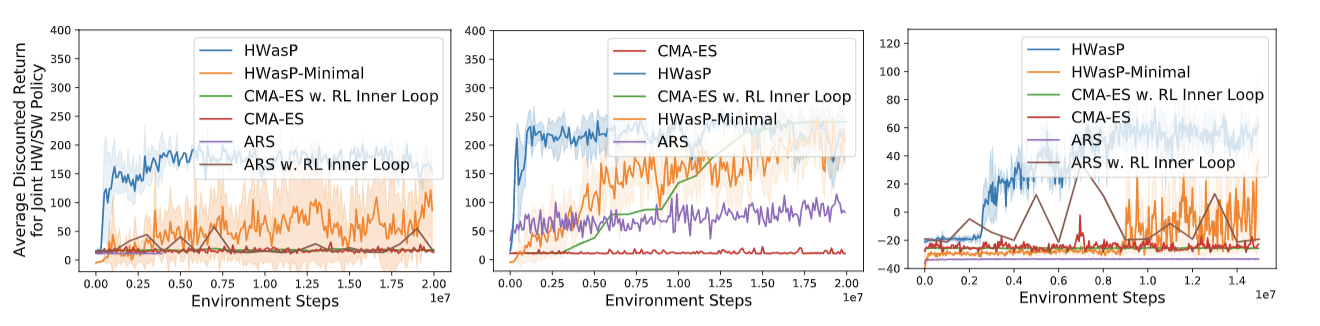
Left: Z-Grasp with a large hardware parameter search range. Here, HWasP learns the task stably while HWasP-Minimal lags in performance. All evolutionary algorithms (CMA-ES and ARS) fail to achieve similar performance as HWasP.
Middle: Z-Grasp with small hardware search range. We also tried a version of the same problem with the search range for the hardware parameters reduced by a factor of 8. Here, all methods except CMA-ES obtain similarly effective policies, but HWasP is still most efficient. ARS achieve better performance than CMA-ES while optimizing both the computational policy and hardware parameters.
Right: 3D-Grasp with a small search range. With this task, HWasP was able to learn an effective policy, while neither CMA-ES-based method displayed any learning behavior over a similar timescale.
Physical Hardware Prototyping and Policy Deployment in Realworld
To validate our results in the real world, we physically built the hand with the parameters resulted from the co-optimization. The hand is 3D printed, and actuated by a single position-controlled servo motor. We note that, by virtue of a large number of simulation samples of different grasp types with different object shapes, sizes and other physics properties, the hand is versatile and can perform both stable fingertip grasps as well as enveloping grasps for different objects in reality.
Acknowledgements
The authors would like to thank Roberto Calandra for insightful discussions and suggestions. This work was supported in part by ONR Grant N00014-16-1-2026 and by a Google Faculty Award.
Contact
If you have any questions, please feel free to contact Zhanpeng He