Abstract
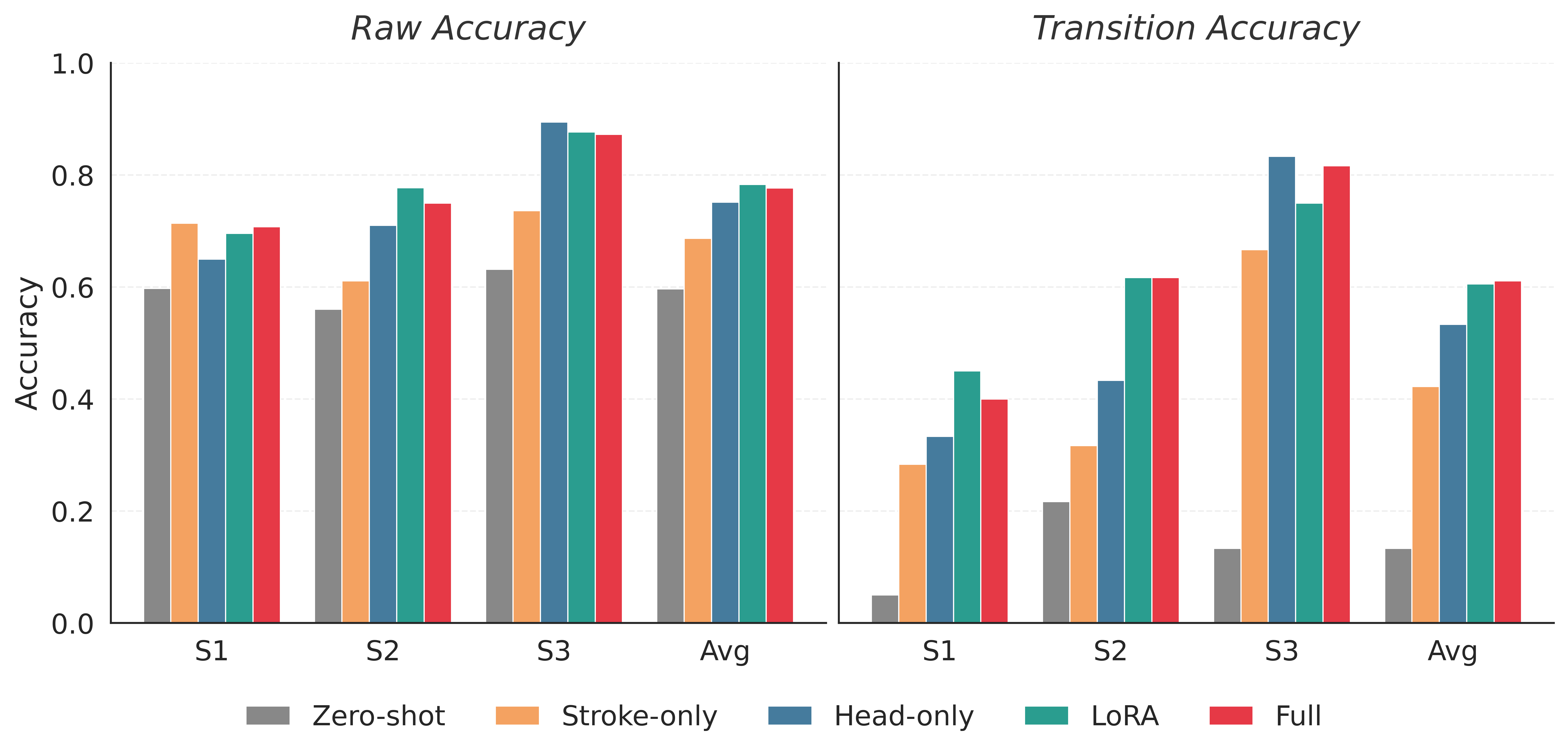
Surface electromyography (sEMG) is a promising control signal for assist-as-needed hand rehabilitation after stroke, but detecting intent from paretic muscles often requires lengthy, subject-specific calibration and remains brittle to variability. We propose a healthy-to-stroke adaptation pipeline that initializes an intent detector from a model pretrained on large-scale able-bodied sEMG, then fine-tunes it for each stroke participant using only a small amount of subject-specific data. Using a newly collected dataset from three individuals with chronic stroke, we compare adaptation strategies (head-only tuning, parameter-efficient LoRA adapters, and full end-to-end fine-tuning) and evaluate on held-out test sets that include realistic distribution shifts such as within-session drift, posture changes, and armband repositioning. Across conditions, healthy-pretrained adaptation consistently improves stroke intent detection relative to both zero-shot transfer and stroke-only training under the same data budget; the best adaptation methods improve average transition accuracy from 0.42 to 0.61 and raw accuracy from 0.69 to 0.78. These results suggest that transferring a reusable healthy-domain EMG representation can reduce calibration burden while improving robustness for real-time post-stroke intent detection.